在 SEQ 的结构中,一条指令必须等到它之前的指令执行完毕,才能被执行。
通过流水线技术,可以增加系统的 吞吐量(throughput),也就是单位时间内执行的指令数量。
执行一条指令所花费的时间称为 延迟(latency)。
计算流水线
计算流水线:即,将一个指令的执行过程拆分为多个阶段,每个阶段完成指令执行的一部分。
这样,一条指令不必等到它之前的指令执行完毕才开始执行,
为了保存指令在某个阶段的状态并传输给下一个阶段,在各个阶段之间会放入 流水线寄存器(pipeline registers)。
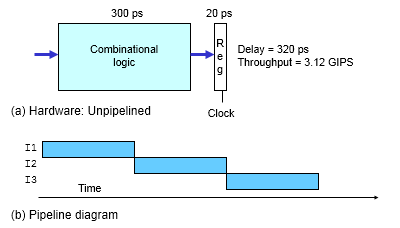
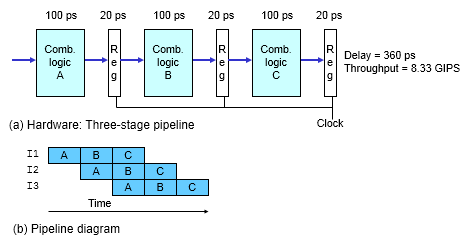
上例中,非流水线化的计算硬件需要 320 ps 执行一条指令,而流水线化的计算硬件在 120 ps 即可执行一条指令。
局限性
可以使用如下公式来计算吞吐量:
$$throughput = {1 \over {t + T / n}}$$
上式中,t 为流水线寄存器所产生的的延迟;T 指令的延迟(不含在流水线寄存器上的延迟);n 为流水线上的阶段数。
由公式可见:
-
在其他参数不变的情况下,流水线越深(n 越大),系统的吞吐量越大;
而现实是,处理器中的某些硬件单元,如 ALU 和存储器是不能被划分为多个延迟较小的单元的,这就限制了流水线的深度。
-
对于流水线,系统的吞吐量受到速度最慢的阶段所限制,因为我们必须按照速度最慢的阶段来设定时钟周期,这会造成 T 变大,吞吐量变小。
所以需要尽量按照个部件处理信号的顺序、延迟等,把他们划分到合适的阶段,使得不同的阶段具有相同的延迟。
-
当流水线足够深时,流水线寄存器的延迟就成为了一个重要的限制因素。
现代处理器采用了很深的流水线——15 或更多的阶段。
显然,流水线越深,指令的延迟越大,不过这并不那么重要。
相互关联的指令
很多指令需要使用其之前的指令的执行结果,例如:
-
数据相关(data depandency),例如:
irmovl $50 %eax addl %eax, %ebx -
控制相关(control dependecy),例如:
subl %edx, %ebx jne targ
顺序执行时,下一条指令都是在之前指令执行完毕后才执行的所以不存在问题。
而对于流水线来说,下一条指令开始执行时(即进入取指阶段),上一条指令才刚刚进入译码阶段。必须以某种方式来处理指令间的数据和控制相关,相关内容见下一篇文章:数据冒险。
Y86 的流水线实现
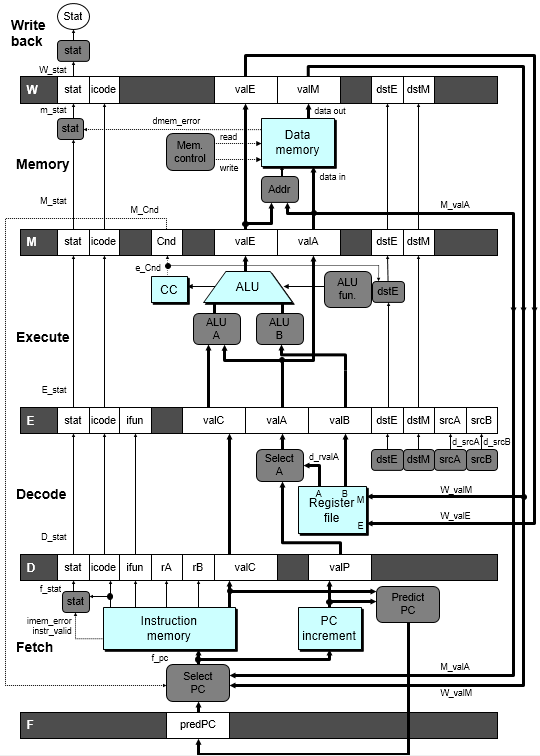
信号命名规则:
-
存储在流水线寄存器中的参数:前面加上大写的流水线寄存器的名字作为前缀,如 E_valA。
-
在某阶段刚输出的参数:前面加上小写的阶段名的首字母作为前缀,如 e_valE。
将 Y86 从 SEQ 改造为流水线实现 PIPE-,主要需要关注的有:
-
将 PC 的计算移动到了取指阶段;
这种对状态元素的改进称为 电路重定时(circuit retiming)。重定时改变了一个系统状态的表示,但是不改变它的逻辑行为。通常用来平衡一个系统中一个系统中各个阶段的延迟。
在 PIPE- 中,没有硬件寄存器对应 PC。CPU 不需要在硬件实现上和程序员可见状态相对应,只要能够为任意的程序员可见状态产生正确的值即可。
除了平衡各阶段的延迟,我认为更为重要的是:流水线的实现要求我们在取指阶段就能够获知下一条指令的地址。
除了条件转移指令和 ret 以外,在取指阶段中,我们能够确定下一条指令的地址:call 和 jmp 就是常数字 valC,其他指令则为 valP。
-
条件转移指令,简单起见,总是预测选择了条件;那么我们就要处理预测失败的情况。
-
ret 则暂停处理新指令,直到 ret 指令通过写回阶段。
条件转移指令和 ret 的处理将在下一篇文章:数据冒险中详述。
-
-
在各个阶段之间加上了流水线寄存器;
-
译码阶段添加了 Select A 的块。
这主要是为了减少携带给流水线寄存器 E 和 M 的状态数量。
在所有指令的执行、访存和写回阶段中,call 指令在访存阶段使用到了 valP,条件跳转指令在无需跳转时使用到了 valP,且这些指令都不使用 valA,所以此处进行了信号的合并。
可以查看《实现 Y86 处理器 —— 指令执行分析及顺序实现》文中追踪指令的执行的表格。
“条件跳转指令在无需跳转时使用到了 valP”涉及到流水线冒险,将在下节中介绍。
另外,顺序执行的更新 PC 阶段已经移动到了取指阶段,所以不需要考虑更新 PC 阶段还要用到 valP。
在硬件设计中,确认信号是如何使用的,然后通过信号合并来减少寄存器状态和线路的数量,是很常见的。
关于 PIPE- 其他细节不必过于深究,在有关 PIPE 的章节中会详细剖析。