我们初步要实现的处理器是顺序的,即完全执行完一条指令才执行下一条指令。
通常,会将不同的指令分解成相同的阶段序列,这样有利于简化处理器设计及充分利用硬件。
下面是各阶段的简略描述:
将处理组织成阶段
-
取指(fetch):按 PC 保存的地址从存储器读取指令字节,并计算出紧邻的下一条指令的地址 valP。
-
译码(decode):从寄存器文件中读入所需的操作数 valA 和\或 valB。
-
执行(execute):该阶段计算出的值称为 valE。
-
访存(memory):从存储器读出数据 valM,或向存储器写入数据。
-
写回(write back):最多可以写两个结果到寄存器文件。
-
更新 PC(PC update):将 PC 设置成下一条指令的地址。
追踪指令的执行
下表略去了取指阶段。
| 指令 | 译码 | 执行 | 访存 | 写回 | 更新 PC |
|---|---|---|---|---|---|
| cmovxx rA, rB | valA←R[rA] | valE←0+valA Cnd←Cond(cc, ifun) |
if(Cnd) R[rB]←valE |
PC←valP | |
| irmovl V, rB | valE←0+valC | R[rB]←valE | PC←valP | ||
| rmmovl rA, D(rB) | valA←R[rA] valB←R[rB] |
valE←valB+valC | M[valE]←valA | PC←valP | |
| mrmovl D(rB), rA | valA←R[rA] valB←R[rB] |
valE←valB+valC | valM←M[valE] | R[rA]←valM | PC←valP |
| OPl rA, rB | valA←R[rA] valB←R[rB] |
valE←valB OP valA set CC |
R[rB]←valE | PC←valP | |
| JXX Dest | Cnd←Cond(cc, ifun) | PC←Cnd?valC:valP | |||
| call Dest | valB←R[%esp] | valE←valB-4 | M[valE]←valP | R[%esp]←valE | PC←valC |
| ret | valA←R[%esp] valB←R[%esp] |
valE←valB+4 | valM←M[valA] | R[%esp]←valE | PC←valM |
| pushl rA | valA←R[rA] valB←R[%esp] |
valE←valB-4 | M[valE]←valA | R[%esp]←valE | PC←valP |
| popl rA | valA←R[%esp] valB←R[%esp] |
valE←valB+4 | valM←M[valA] | R[%esp]←valE R[rA]←valM |
PC←valP |
下面来分析一下上表中对各个指令执行的追踪情况,并为各阶段使用的硬件接入输入信号。
译码和写回阶段
观察译码和写回阶段可以看出:需要一个可以同时读取两个寄存器、同时写入两个寄存器的寄存器文件。
valA 读取地址可能是 rA 或 %esp,valB 读取地址可能是 rB 或 %esp。
valM 写入地址可能是 rA,valE 写入地址可能是 rB 或 %esp。
callretpushlpopl指令在译码阶段都会获取 %esp 寄存器的数据,在写回阶段会更新 %esp 的数据。这几条指令都会对栈进行操作。
对于 cmovxx 指令,还需要 Cnd 值以判断是否写入 valE。
所以,可以如下配置信号输入:
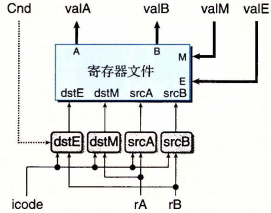
总结上表可以写出 srcA 这个组合电路的 HCL 表达式:
int srcA = [
icode in { IRRMOVL, IRMMOVL, IOPL, IPUSHL } : rA;
icode in { IPOPL, IRET } : RESP;
1: RNONE;
];
类似地,可以写出其他组合电路的 HCL 表达式。
注意:
图中的矩形表示硬件单元;圆角矩形表示控制逻辑。
图中不同样式的线代表不同的传输宽度:粗线表示宽度为字长;细线表示字节或更窄;虚线表示单个位。
执行阶段
注意 mrmovl D(rB), rA 指令,为什么使用 D(rB), rA 而不是 D(rA), rB 呢?
观察上表的执行阶段可以发现,只存在 valA 和 valB 之间、valB 和 valC 之间的运算,而不存在 valA 和 valC 之间的运算。
这样,就可以使得 ALU 的一个数据输入直接接入 valB;而另一个数据输入则可使用一个 MUX的输出,该 MUX 以 valA 和 valC 为输入,icode 为控制信号。
这样的设计是比较简单的。
所以,可以如下配置信号输入:
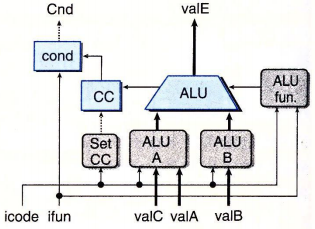
ALU fun. 是 ALU 的控制器。
对于 OPl 指令,它的输出和 OPl 的功能码 ifun 一致;其他指令,均使用加法操作即可。
int alufun = [
icode == IOPL : ifun;
1 : ALUADD;
]
另外,我们只希望在 OPl 指令时才设置条件码,图中的 SetCC 就是控制是否使用条件码寄存器 CC 的。
bool set_cc = icode in { IOPL };
不同指令在执行阶段的操作:
-
对于 OPl 指令(icode = 2),要根据 ifun 代码,计算结果,并可能设置条件码。
-
对于
rmmovlmrmovl指令,要计算存储器的有效地址。 -
对于
callretpushlpopl指令,则要计算 %esp 的新值。 -
对于 JXX 和 CMOV 指令,则要根据 ifun 和 CC 计算 Cnd 值(表示是否执行指令)。
这里有个问题,为什么 cond 要使用一个硬件,而不是控制逻辑?
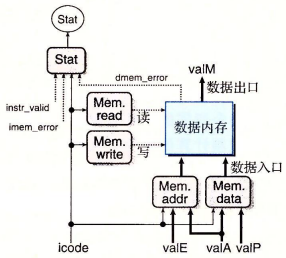
访存阶段
观察访存阶段可以总结出:
-
写入指令:
rmmovlcallpushl -
读取指令:
mrmovlretpopl -
存储器地址输入可能是 valE 或 valA,写入值可能是 valA 或 valP。
观察 ret 和 popl rA 可以看到,对于二者,valA 和 valB 是相同的值,但是它们都选择了 valA 作为存储器地址使用。正式因为这种一致性,我们最终只需要在 valE 和 valA 筛选出一个作为地址输送给存储器。
所以,可以如下配置信号输入:
更新 PC 阶段
观察更新 PC 阶段,可能的值有:valC(jmp;call 或 JXX 为 Cnd = 1 时);valM(ret);valP。
所以,可以如下配置信号输入:
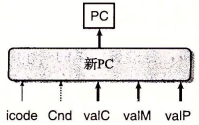
取指阶段
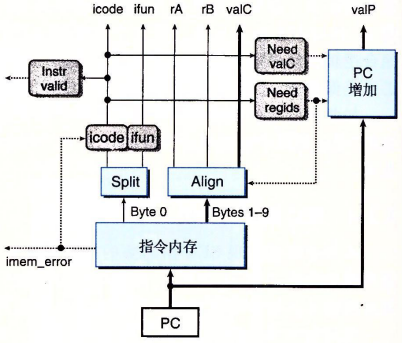
从指令存储器取出指令后,首字节被保存到 Split 中,其他字节被保存到 Align 中。
首字节被拆分为 icode 和 ifun;而 icode 又被拆分为 Need regids 和 Need valC。
根据 Need regids 和 Need valC,PC 增加单元就能够计算出下一条指令的地址。
根据 Need regids,Align 就能够知道如何处理其保存的字节:
- need_regids == 1 则拆分其保存的首字节为 rA 和 rB 输出,并将后面的字节作为 valC 输出。
- need_regids == 0 则将其保存的 0 ~ 3 字节作为 valC 输出。
注意:Align 并不需要 Need valC 这个信号的控制。
SEQ 处理器
将上面使用到的各个模块,按照信号的传递顺序连接起来,就形成了一个 SEQ(sequential 顺序的)处理器。
在 SEQ 中所有硬件单元的处理都在一个时钟周期内完成。
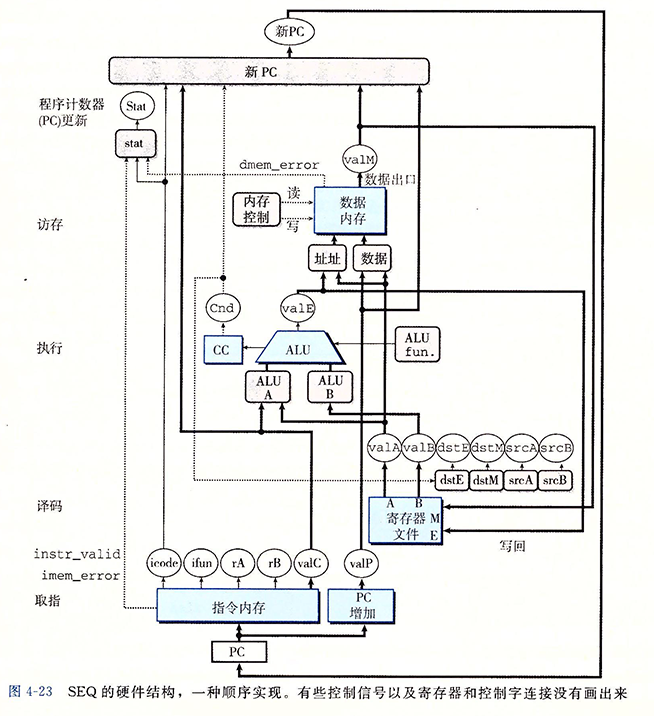
上图的白色椭圆中标注了线路的名字,并非硬件或控制逻辑等。
状态码
这里需要补充说一下异常状态码。
在取指阶段可能会产生 imem_error(指令地址不合法)和 instr_valid(不合法的指令)两个异常。
在取指阶段的示意图中,可以看到 icode 单元受到 imem_error 的控制,当 imem_error 异常出现时,将会执行 nop 指令。
在访存阶段,数据存储器可能会产生 dmem_error 异常,读取或写入地址不合法。
在访存阶段,这三种异常和 icode 一起经过 Stat 单元计算出状态码。
SEQ 只是一个过度的模型,无需深究其异常处理。